A Reexamination of Schema
Implementing Materialized Views to Reduce Load Times
The Reddit crawler that I wrote runs every 15 minutes and stores every word used more than once during that period of time. As you may imagine, the database grew quite quickly. Roughly one year after the projects inception, the database now contains more than 12 million rows. Performance gradually decreased and the database design that I initally created needed to be refactored.
Before diving in to the specific changes that I made, let's set some benchmarks.
| API Call | Time Elapsed |
|---|---|
| /topwords?interval=day | ~12-15s |
| /topwords?interval=month | ~15-20s |
| /topwords?interval=year | ~25-30s |
| /topwords?interval=custom | ~30s |
| /search | ~30s |
The database schema looked this:
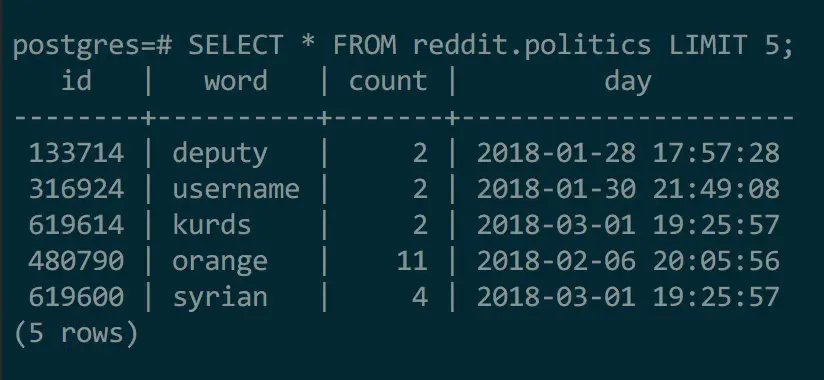
Notice that the last column is a datetime. The data that I really needed, however, was a date. This resulted in a lot of operations casting this column to a date (e.g. date_trunc(day, 'date')). I indexed the 'day' column, but these operations did not take advantage of the index, resulting in very slow queries.
ßTo fix this issue, I renamed the 'day' column to 'full_date' and then created a true 'day' column with a corresponding index.
The database schema now looks like this:
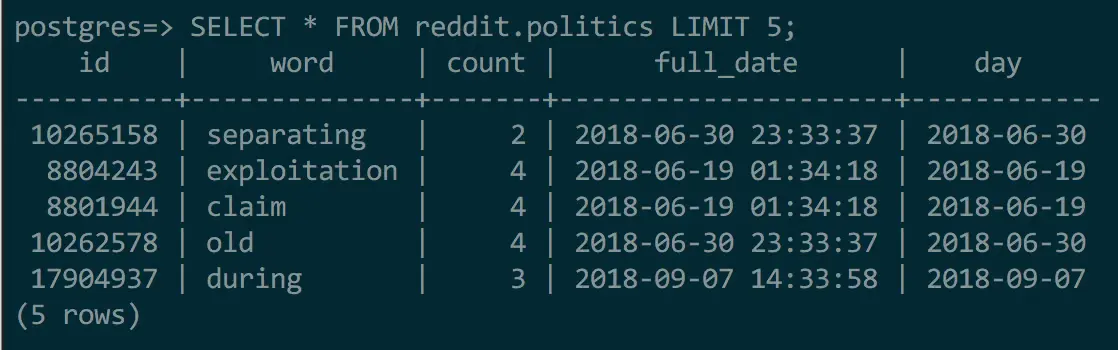
This change improved performance significantly, reducing load times by about 30%, to between 9-20s. While a step in the right direction, the application was not nearly snappy enough.
All of my queries involved summation of word counts over multiple days and distinct crawler runs (e.g. find the 10 most common words over the last day, month, year or get sum for everyday the word is present in the database). Additionally, since I was interested in word usage rates, I also needed total word counts for each time period. Enter the materialized view.
Here is the definition for a few of the materialized views I use in this application.
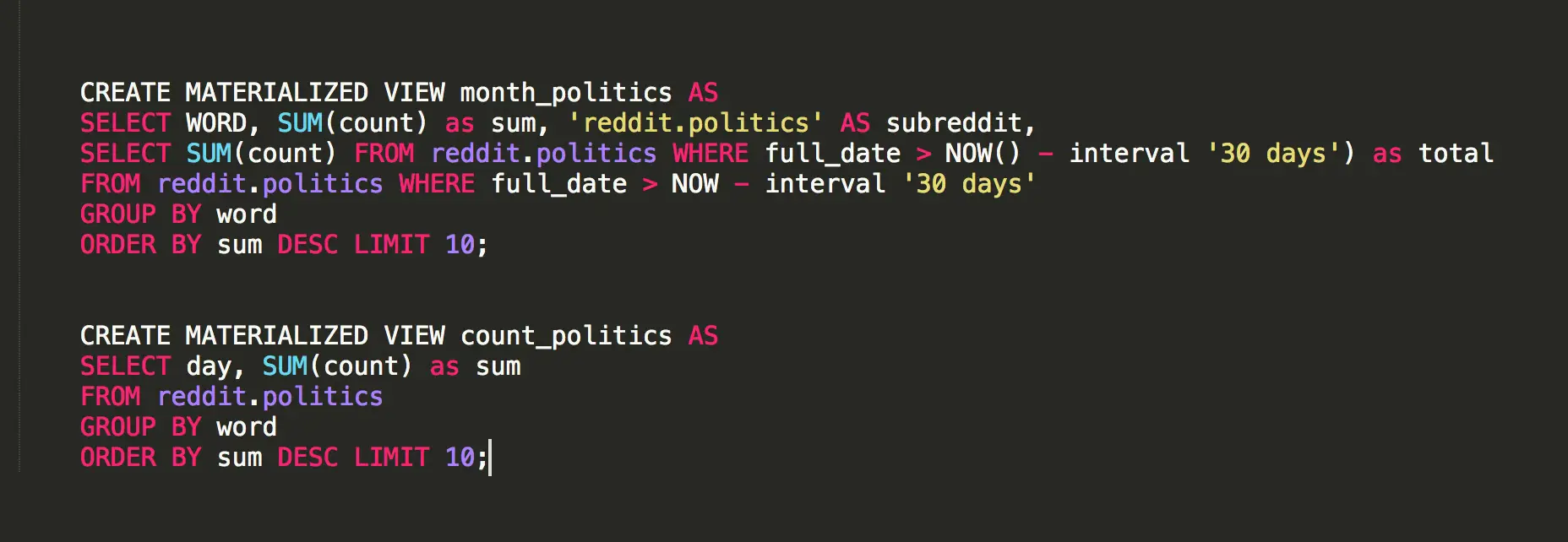
What makes materialized views so perfect for this application is the ability to dynamically refresh the view. In this case, I just refresh the materialized views at the end of each crawler run, preprocessing the data that needs to be returned for each API call. Here are a few examples of what these ultimately look like.
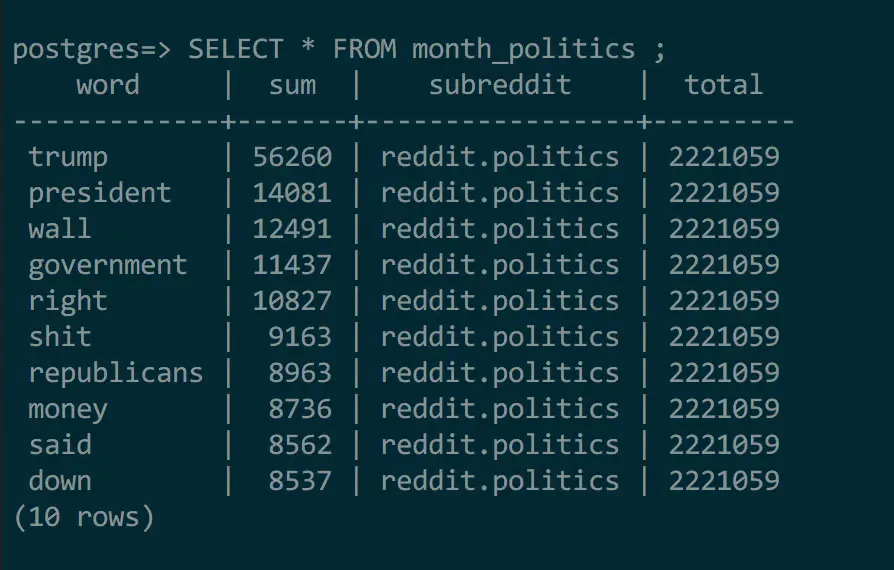
The creation of these materialized views (and the corresponding API manager refactor) resulted in enormous performance gains. The crawler, in effect, now takes on the work of compiling the expensive summation queries. This happens behind the scenes, instead of at request time. I encourage you to take a look at the SQL queries I now use to fetch the data for these pages.
In conclusion, let's take a look at the current benchmarks for the API calls against the Reddit databases. All in all, I am really pleased with this effort. I learned a ton about database design, materialized views, and indexes.
| API Call | Time Elapsed |
|---|---|
| /topwords?interval=day | <.5s |
| /topwords?interval=month | <.5s |
| /topwords?interval=year | <.5s |
| /topwords?interval=custom | ~3s |
| /search | ~3s |