A Note About Outages
Implementing PSQL's VACUUM Functionality to Manage Disk Space
Every fifteen minutes, my crawler runs and counts the words used in the top comments on a few subreddits. Each crawler run adds thousands of rows to my PSQL database. I only store one year of data for each of the subreddits that I track, so each crawler run also deletes thousands of rows from my PSQL database. The data that is older than that is purged via a database cleanup script tied to the crawler. I figured that this system would exist in equilibrium - an amount of data coming in and an equal amount being removed. This was not the case.
In fact, in normal operation, a DELETE operation in a PSQL database does not truly delete the record. The record exists, hidden, and linked to a transaction referred to as an UNDO. An UPDATE operation, which actually performs a DELETE followed by an INSERT, functions in a similar manner. These leftover records accumulated in my system for months. These leftover records are referred to as 'dead tuples' or 'bloat.' The result, on my t2.micro EC2 instance with 16Gb of storage space, is as follows:
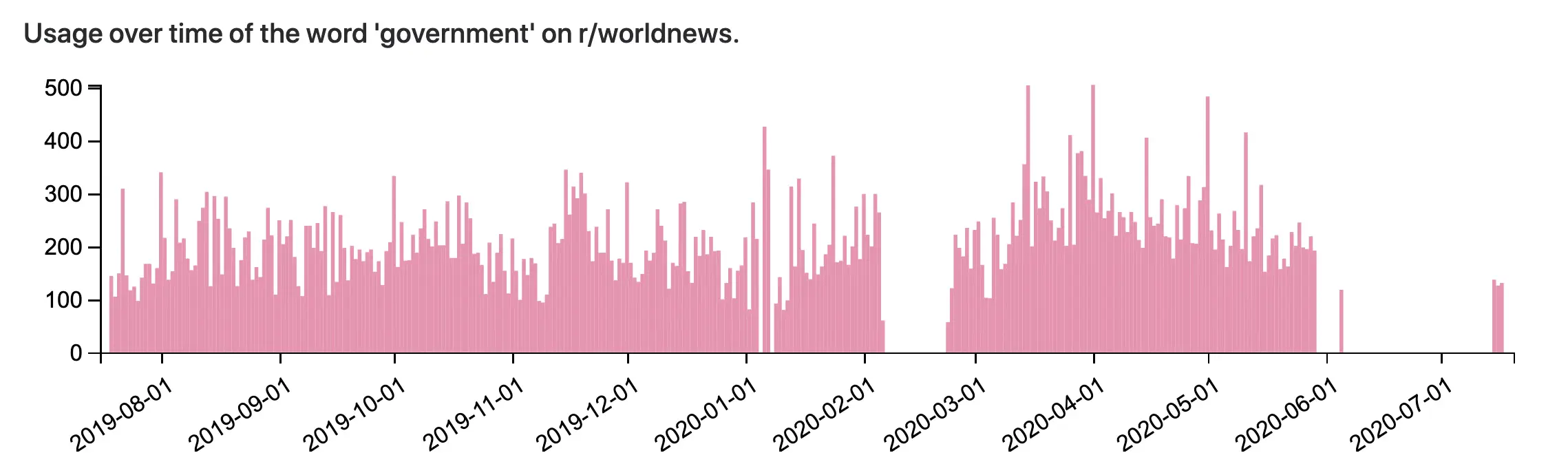
I ran out of disk space and my crawler stopped working. Twice! The first outage was in early February, just after the 2020 Superbowl. I collected a few milion Tweets from the game and hit the disk space wall. I didn't notice that the crawler was not operational for a few weeks. When I did, I backed out the Tweets, cleaned up some old packages I wasn't using anymore, and away I went.
The second outage lasted a bit longer. My life was in complete limbo as I moved between Querétaro, Portland, and Poulsbo and the Coronavirus swept across the nation and world. Or at least that is my excuse for not fixing my crawler for a few months.
This outage was a bit more challenging to resolve. My EC2 instance was at 100% disk capacity, only a few bytes were free. I couldn't connect to the database instance. So I first had to remove the site files, Python packages, and log files to enter the PSQL database. This freed up enough space to allow me to run a VACUUM operation.
There are two varieties of VACUUM operation- VACUUM and VACUUM FULL. VACUUM removes the dead tuples from the database and marks the freed up space to be used for future operations, but does not reclaim the disk space. VACUUM is a non-blocking operation. In other words, the site and database can be used while the process is ongoing. VACUUM FULL removes the dead tuples and allows the disk to reclaim the space. It is a blocking operation - you can not read or write to a table while VACUUM FULL is in progress.
The next figures demonstrate the available disk space before and after a VACUUM FULL.
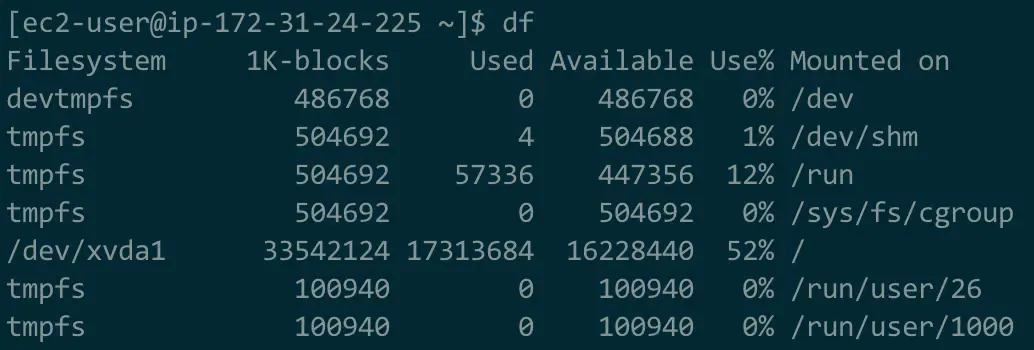
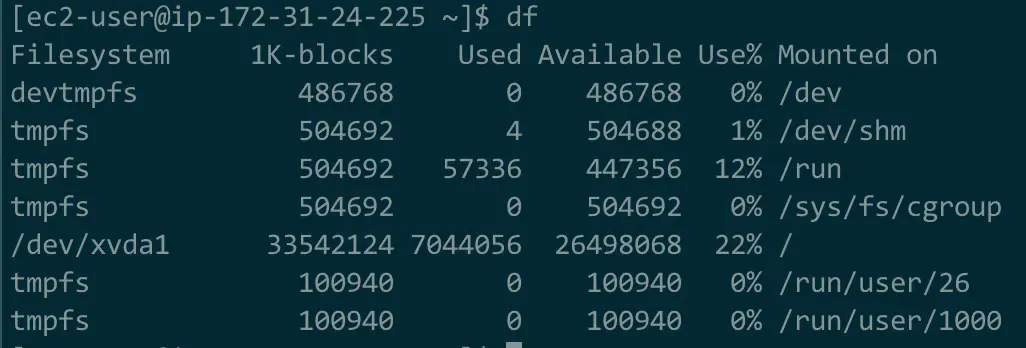
The constant writes, deletes, and updates generated by a crawler like this create a lot of database bloat. I did not fully appreciate this aspect of database management when I deployed the application. In response to these problems, I now run a weekly VACUUM and have a scheduled montlhy maintenance window where I drop the site, run a VACUUM FULL, and rebuild database indexes.
This has kept the disk space usage well under control. You may also have noticed in the images above that I have sprung for an additional 16Gb of space on my EC2 instance. My monthly hosting cost rose by $4! What can I say, I'm a big spender.
If you would like to learn more, you can find PSQL's VACUUM documentation here. I also found Avinash Vallarapu's excellent article Understanding of Bloat and VACUUM in PostgreSQL very helpful while working to resolve this issue.